



La start-up chinoise DeepSeek frappe à nouveau avec une mise à jour majeure de son modèle V3. Cette nouvelle version baptisée DeepSeek-V3-0324 affiche des performances impressionnantes qui rivalisent désormais avec les géants américains de l'IA.
 Après avoir secoué l'industrie de l'intelligence artificielle avec son modèle R1 il y a deux mois, DeepSeek poursuit sa montée en puissance avec une mise à jour significative de son modèle V3. Cette nouvelle itération, moins médiatisée que R1 mais tout aussi prometteuse, s'appuie sur l'architecture MoE (Mixture of Experts) qui avait déjà impressionné les spécialistes. Contrairement à R1 qui est axé sur le raisonnement, V3-0324 se positionne comme un modèle fondamental polyvalent avec des capacités améliorées en codage et en mathématiques.
Après avoir secoué l'industrie de l'intelligence artificielle avec son modèle R1 il y a deux mois, DeepSeek poursuit sa montée en puissance avec une mise à jour significative de son modèle V3. Cette nouvelle itération, moins médiatisée que R1 mais tout aussi prometteuse, s'appuie sur l'architecture MoE (Mixture of Experts) qui avait déjà impressionné les spécialistes. Contrairement à R1 qui est axé sur le raisonnement, V3-0324 se positionne comme un modèle fondamental polyvalent avec des capacités améliorées en codage et en mathématiques.DeepSeek : un retour stratégique avec V3-0324
La mise à jour V3-0324 marque une progression remarquable dans plusieurs domaines clés. Selon les benchmarks publiés par l'entreprise, le modèle affiche une amélioration de près de 20 points dans l'examen américain de mathématiques AIME, passant de 39,6 à 59,4, et une augmentation de 10 points dans le test de codage LiveCodeBench.
Cette progression s'explique notamment par l'architecture MoE (Mixture of Experts), qui constitue une approche différente des modèles d'IA traditionnels. Au lieu d'activer l'ensemble de ses paramètres pour chaque tâche, DeepSeek-V3-0324 n'utilise qu'environ 37 milliards de ses 685 milliards de paramètres pour traiter une requête spécifique, sollicitant ses différents groupes de paramètres, nommés « experts » dynamiquement.
Le modèle intègre également deux innovations majeures : le Multi-Head Latent Attention (MLA) qui améliore la gestion du contexte dans les textes longs, et le Multi-Token Prediction (MTP) permettant de générer plusieurs tokens simultanément. Cette combinaison technologique augmente la vitesse de sortie de près de 80%, un avantage considérable par rapport aux modèles concurrents, d'autant qu'il s'agit toujours d'un modèle open-source.
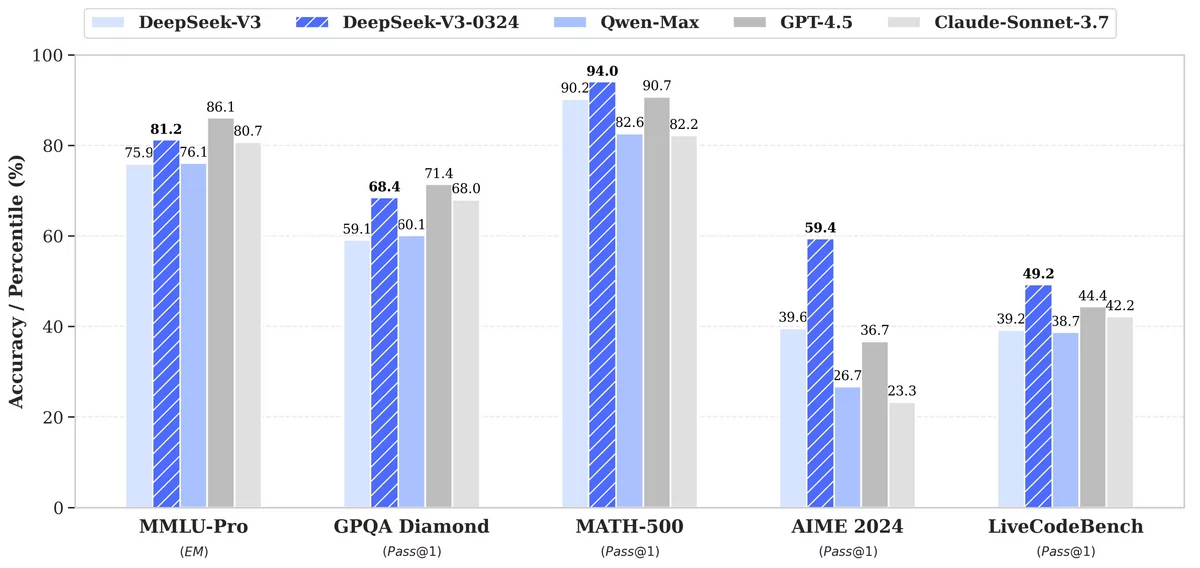
Benchmarks de Deepseek V3-0324 - © Deepseek Un modèle ouvert et économiquement avantageux
Contrairement à la tendance du secteur où les modèles les plus performants sont souvent inaccessibles ou payants, DeepSeek a choisi une approche radicalement différente. V3-0324 est disponible gratuitement sur la plateforme Hugging Face sous licence MIT, ce qui autorise son utilisation commerciale sans restriction. Cette stratégie d'ouverture s'inscrit dans la philosophie que DeepSeek a développée depuis sa création. Issue d'un fonds d'investissement quantitatif, la start-up a toujours privilégié l'efficience et l'optimisation des ressources face aux restrictions américaines sur les GPU imposées aux entreprises chinoises.
L'efficacité de son architecture permet également de réduire considérablement les coûts d'exploitation. Alors que les modèles occidentaux comme GPT-4.5 ou Claude nécessitent d'importants budgets cloud, V3-0324 offre des performances comparables à un coût nettement inférieur. Une version quantifiée en 2.71 bits réduit même la taille du modèle à 231 Go, le rendant accessible sur certains matériels haut de gamme comme le Mac Studio équipé d'une puce M3 Ultra.
merci à CLUBIC
